1. Quarkus-Projekt initialisieren und Dependencies hinzufügen
Details
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-hibernate-orm-panache</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-jdbc-postgresql</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-hibernate-orm</artifactId>
</dependency>
<dependency>
<groupId>io.quarkiverse.jpastreamer</groupId>
<artifactId>quarkus-jpastreamer</artifactId>
<version>3.0.3.Final</version>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-hibernate-validator</artifactId>
</dependency>| Das Hinzufügen der Dependency für die MCP-Kommunikation erfolgt zu einem späteren Zeitpunkt. |
2. JDBC Datasource hinzufügen
Mehr dazu: Quarkus: JDBC Datasource hinzufügen
3. Entities
Teacher repräsentiert eine Lehrkaft mit dem Vor- und Nachnamen.
OfficeHour repräsentiert eine Sprechstunde mit der Lehrkaft und Details der Sprechstunde.
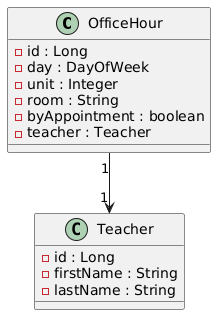
Details
package at.htlleonding.officehoursmcp.entity;
import jakarta.persistence.*;
@Entity
@Table(name = "OHMCP_TEACHER")
public class Teacher {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "T_ID")
private Long id;
@Column(name = "T_FIRST_NAME")
private String firstName;
@Column(name = "T_LAST_NAME")
private String lastName;
// getter & setter
@Override
public String toString() {
return "Teacher{" +
"id=" + id +
", firstName='" + firstName + '\'' +
", lastName='" + lastName + '\'' +
'}';
}
}package at.htlleonding.officehoursmcp.entity;
import jakarta.persistence.*;
import jakarta.validation.constraints.NotNull;
import java.time.DayOfWeek;
@Entity
@Table(name = "OHMCP_OFFICE_HOUR")
public class OfficeHour {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "OH_ID")
private Long id;
@OneToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "OH_TEACHER")
@NotNull
private Teacher teacher;
@Column(name = "OH_DAY")
private DayOfWeek day;
@Column(name = "OH_UNIT")
private Integer unit;
@Column(name = "OH_ROOM")
private String room;
@Column(name = "OH_BY_APPOINTMENT")
private boolean byAppointment;
// getter & setter
@Override
public String toString() {
return "OfficeHour{" +
"id=" + id +
", teacher=" + teacher +
", day=" + day +
", unit=" + unit +
", room='" + room + '\'' +
", byAppointment=" + byAppointment +
'}';
}
}4. Repositories
Die Repositories werden mit Panache implementiert:
Der Rückgabetyp aller Abfragen ist String, da die MCP-Tools nur damit kompatibel sind.
JPAStreamer wurde verwendet, um JPA-Queries als Streams auszudrücken.
Details
package at.htlleonding.officehoursmcp.repository;
import at.htlleonding.officehoursmcp.entity.Teacher;
import com.speedment.jpastreamer.application.JPAStreamer;
import io.quarkus.hibernate.orm.panache.PanacheRepository;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import java.util.stream.Collectors;
@ApplicationScoped
public class TeacherRepository implements PanacheRepository<Teacher> {
@Inject
JPAStreamer jpaStreamer;
public String getAllTeachersAsString() { (1)
String teachers = jpaStreamer.stream(Teacher.class)
.map(Teacher::getFullName)
.collect(Collectors.joining(", "));
return teachers.isEmpty()
? "Keine Lehrer in der Datenbank gefunden."
: teachers;
}
}| 1 | getAllTeachersAsString() gibt eine Liste aller Lehrkräfte als String zurück. |
package at.htlleonding.officehoursmcp.repository;
import at.htlleonding.officehoursmcp.entity.OfficeHour;
import com.speedment.jpastreamer.application.JPAStreamer;
import io.quarkus.hibernate.orm.panache.PanacheRepository;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import java.util.stream.Collectors;
@ApplicationScoped
public class OfficeHourRepository implements PanacheRepository<OfficeHour> {
@Inject
JPAStreamer jpaStreamer;
public String getAllOfficeHoursByTeacherNameAsString(String name) { (1)
String finalName = name.toLowerCase().trim();
String officeHours = jpaStreamer.stream(OfficeHour.class)
.filter(oh -> oh.getTeacher() != null && oh.getTeacher().getFullName().toLowerCase().contains(finalName))
.map(OfficeHour::toString)
.collect(Collectors.joining(", "));
return officeHours.isEmpty()
? "Keine Sprechstundendaten zu Lehrerin oder Lehrer %s gefunden!".formatted(finalName)
: officeHours;
}
public String getTeachersByRoom(String room) { (2)
String finalRoom = room.toLowerCase().trim().replace("_", "");
String teachers = jpaStreamer.stream(OfficeHour.class)
.filter(oh -> oh.getRoom() != null && oh.getRoom().toLowerCase().replace("_", "").contains(finalRoom))
.map(oh -> oh.getTeacher().toString())
.collect(Collectors.joining(", "));
return teachers.isEmpty()
? "Keine Lehrerinnen und Lehrer in Raum %s gefunden!".formatted(finalRoom)
: teachers;
}
}| 1 | getAllOfficeHoursByTeacherNameAsString(String name) gibt die Sprechstundendaten basierend auf dem Vor- und/oder Nachnamen einer Lehrkraft zurück. |
| 2 | getTeachersByRoom(String room) gibt alle Lehrkräfte aus einem Raum (Büro) zurück. |
5. CSV-Reader
Die Sprechstundendaten liegen im CSV-Format bereit (Separator: Tabulator).
Lehrkraft Wochentag Datum Std. Von Bis Raum
Aberger Christian Dienstag 25.03.2025 3. EH 10:00 10:50 LK_E74
Aistleitner Gerald Montag 24.03.2025 6. EH 12:45 13:35 LK_206
Bodenstorfer Bernhard Nach Vereinbarung! 0 - 0. EHDiese werden beim Hochfahren der Applikation eingelesen und in der Datenbank gespeichert:
Details
Dateipfad in application.properties festlegen:
officehours-csv-path=htlleonding-officehours-24-25.csvFolgender Parser wird verwendet, um einen deutschen Wochentagsname in ein DayOfWeek-Enum zu konvertieren:
package at.htlleonding.officehoursmcp.parser;
import jakarta.enterprise.context.ApplicationScoped;
import java.time.DayOfWeek;
import java.util.Map;
@ApplicationScoped
public class DayOfWeekParser {
private final Map<String, DayOfWeek> DAY_OF_WEEK_MAP = Map.of(
"MONTAG", DayOfWeek.MONDAY,
"DIENSTAG", DayOfWeek.TUESDAY,
"MITTWOCH", DayOfWeek.WEDNESDAY,
"DONNERSTAG", DayOfWeek.THURSDAY,
"FREITAG", DayOfWeek.FRIDAY
);
public DayOfWeek parse(String dayOfWeek) {
dayOfWeek = dayOfWeek.toUpperCase().trim();
if(DAY_OF_WEEK_MAP.containsKey(dayOfWeek)) {
return DAY_OF_WEEK_MAP.get(dayOfWeek);
} else {
throw new IllegalArgumentException("Invalid day of week: " + dayOfWeek);
}
}
}Beim Hochfahren der Applikation wird readCsvAndInsert aufgerufen, welche die CSV-Daten einliest, normalisiert und in die Datenbank speichert.
package at.htlleonding.officehoursmcp.control;
import at.htlleonding.officehoursmcp.entity.OfficeHour;
import at.htlleonding.officehoursmcp.entity.Teacher;
import at.htlleonding.officehoursmcp.parser.DayOfWeekParser;
import at.htlleonding.officehoursmcp.repository.OfficeHourRepository;
import at.htlleonding.officehoursmcp.repository.TeacherRepository;
import io.quarkus.logging.Log;
import io.quarkus.runtime.StartupEvent;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.event.Observes;
import jakarta.inject.Inject;
import jakarta.transaction.Transactional;
import org.eclipse.microprofile.config.inject.ConfigProperty;
import java.io.InputStream;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
@ApplicationScoped
public class InsertBean {
@Inject
TeacherRepository teacherRepository;
@Inject
OfficeHourRepository officeHourRepository;
@Inject
DayOfWeekParser dayOfWeekParser;
@ConfigProperty(name = "officehours-csv-path")
String officeHoursCsvPath;
@Transactional
void readCsvAndInsert(@Observes StartupEvent event) {
try(InputStream stream = getClass().getClassLoader().getResourceAsStream(officeHoursCsvPath)) {
String[] content = new String(stream.readAllBytes(), StandardCharsets.UTF_8).split("\n");
for(int i = 1; i < Arrays.stream(content).count(); i++) {
String[] parts = content[i].split("\t");
Teacher teacher = new Teacher();
teacher.setLastName(parts[0].split(" ")[0].trim());
teacher.setFirstName(parts[0].split(" ")[1].trim());
teacherRepository.persist(teacher);
OfficeHour officeHour = new OfficeHour();
officeHour.setTeacher(teacher);
if(parts[1].trim().toLowerCase().contains("vereinbarung")) {
officeHour.setByAppointment(true);
} else {
officeHour.setByAppointment(false);
officeHour.setDay(dayOfWeekParser.parse(parts[1]));
officeHour.setUnit(Integer.parseInt(parts[3].split("\\.")[0]));
if(Arrays.stream(parts).count() >= 7){
officeHour.setRoom(parts[6]);
}
}
officeHourRepository.persist(officeHour);
}
Log.infof("%d teachers in database", teacherRepository.count());
Log.infof("%d officeHours in database", officeHourRepository.count());
} catch (Exception e) {
Log.errorf("Error reading csv-file");
throw new RuntimeException(e);
}
}
}Fertig! Nun haben wir eine Applikation mit einem Datenbestand, auf der MCP-Tools aufgebaut werden können.