1. Einführung
Das Ziel dieses Tutorials ist es, mithilfe von @ConfigMapping auf Konfigurationen aus verschiedensten Config-Sources zuzugreifen. Besonders ersichtlich wird im Tutorial, welche Config-Source den Vorrang hat, wenn Konfigurationen aus mehreren Sources gelesen werden.
2. Erstellung des Projekts
2.1. Quarkus-Projekt erstellen
2.2. Dependencies hinzufügen
<dependencies>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-resteasy</artifactId> (1)
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-resteasy-jackson</artifactId> (2)
</dependency>
</dependencies>| 1 | Ermöglicht die Erstellung von RESTful Web Services |
| 2 | Ermöglicht Serialisierung und Deserialisierung von JSON zu Java-Objekten |
3. Konfiguration hinzufügen
| In diesem Schritt fügen wir in die application.properties Konfigurationen mit dem prefix custom hinzu. |
application.properties mit Konfigurationswerten befüllen
custom.city=Linz
# list of cities (array)
custom.cities[0]=Vienna (1)
custom.cities[1]=London (1)
custom.cities[2]=Madrid (1)
# nested configuration
custom.other.city=Paris
custom.other.cities[0]=Berlin (1)
custom.other.cities[1]=Chicago (1)
custom.other.cities[2]=Boston (1)| 1 | Um eine Liste von Konfigurationen zu erstellen, wird der Index in eckigen Klammern angegeben. |
4. Zugriff auf die Konfigurationen
Die Konfigurationen wurden im vorherigen Schritt gesetzt, nun möchte man auf diese im Code zugreifen können. Hierbei gibt es zwei Möglichkeiten, welche in den folgenden 2 Abschnitten erklärt werden.
4.1. ConfigProperty
| Diese Option ist nur zur Demonstration gedacht und wird nicht in das Tutorial eingebaut. |
Eine Möglichkeit, um auf die Konfigurationswerte zuzugreifen, bietet die Annotation @ConfigProperty.
ConfigProperty
...
@ConfigProperty(name = "custom.city") (1)
String city;
@ConfigProperty(name = "custom.cities") (1)
List<String> cities;
@ConfigProperty(name = "custom.other.city") (1)
String otherCity;
@ConfigProperty(name = "custom.other.cities") (1)
List<String> otherCities;
...| 1 | Die Annotation @ConfigProperty ermöglicht es, auf die Konfigurationen zuzugreifen und den Wert in die entsprechende Variable zu speichern. Der name-Parameter gibt an, auf welche Konfiguration zugegriffen werden soll. |
4.2. ConfigMapping
| Diese Option ist in das Tutorial einzubauen. |
Eine andere Möglichkeit, um auf die Konfigurationswerte zuzugreifen, bietet die Annotation @ConfigMapping.
ConfigMapping
package at.htl.configdemo.entity;
import io.smallrye.config.ConfigMapping;
import java.util.List;
@ConfigMapping(prefix = "custom") (1)
public interface CustomConfiguration {
String city(); (2)
List<String> cities(); (2)
Other other(); (2)
interface Other { (3)
String city(); (2)
List<String> cities(); (2)
}
}| 1 | Die Annotation @ConfigMapping wird verwendet, um Konfigurationseigenschaften, welche mit einem bestimmten prefix beginnen, zu extrahieren. |
| 2 | Die Methoden in einem @ConfigMapping-annotierten Interface definieren die Konfigurationseigenschaften und deren Datentypen. Der Name der Methode sollte dem Namen der Konfigurationseigenschaft (nach dem prefix) entsprechen. |
| 3 | Nested Configurations können durch das Definieren eines weiteren Interfaces innerhalb des @ConfigMapping-annotierten Interface erstellt werden. |
4.3. Fazit
Der Einsatz der oben vorgestellten Optionen sollte auf Basis der Anforderungen des Projekts entschieden werden.
Die Verwendung von @ConfigProperty eignet sich besonders, wenn nur wenige Konfigurationswerte benötigt werden, die unabhängig voneinander sind. Dieser Ansatz ist einfach und ermöglicht einen direkten Zugriff auf einzelne Konfigurationswerte.
@ConfigMapping hingegen bietet eine strukturierte Lösung für den Umgang mit Konfigurationen. Es ermöglicht die Definition von Interfaces, die verwandte Konfigurationswerte logisch gruppieren und somit eine klare Trennung schaffen. Besonders in großen Projekten sorgt dieser Ansatz für bessere Wartbarkeit und Lesbarkeit des Codes.
Im Tutorial wird @ConfigMapping verwendet, da es den Anforderungen einer komplexen sowie verschachtelten Konfiguration am besten gerecht wird.
5. Default-Values definieren
Beim bisherigen Stand des Projekts werden die Konfigurationen aus den application.properties gelesen. Sollte jedoch ein Wert nicht gesetzt sein, der jedoch im Interface deklariert ist, fliegt eine NoSuchElementException.

5.1. ConfigMapping
Um eine NoSuchElementException zu vermeiden, muss man Default-Values im Interface definieren.
ConfigMapping mit Default-Values
package at.htl.configdemo.entity;
import io.smallrye.config.ConfigMapping;
import io.smallrye.config.WithDefault;
import java.util.List;
import java.util.Optional;
@ConfigMapping(prefix = "custom")
public interface CustomConfiguration {
@WithDefault("Linz") (1)
String city();
Optional<List<String>> cities(); (2)
Other other();
interface Other {
@WithDefault("Paris") (1)
String city();
Optional<List<String>> cities(); (2)
}
}| 1 | @WithDefault injected einen Standardwert, falls keine Konfiguration in jeglichen Config-Sources gesetzt wurde. |
| 2 | Bei Listen funktioniert die @WithDefault-Annotation nicht. Hierbei kommt Optional zum Einsatz, welches ein empty-Optional injected, falls die Konfiguration nicht gesetzt ist. |
5.2. ConfigProperty
| Diese Option ist nur zur Demonstration gedacht und wird nicht in das Tutorial eingebunden. |
ConfigProperty mit Default-Values
@ConfigProperty(name = "greeting.suffix", defaultValue="!") (1)
String suffix;
@ConfigProperty(name = "greeting.name")
Optional<String> name; (2)| 1 | Die defaultValue wird injected, falls die Konfiguration nicht gesetzt ist. |
| 2 | Ein empty-Optional wird injected, falls die Konfiguration nicht gesetzt ist. |
6. Endpoints erstellen
Um die Konfigurationswerte auszugeben, erstellen wir REST-Endpoints. Diese geben die Konfigurationen als JSON-Objekte zurück. Um jedoch auf die Konfigurationen zugreifen zu können, benötigen wir eine Service-Klasse.
Service-Klasse
package at.htl.configdemo.control;
import at.htl.configdemo.entity.CustomConfiguration;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import java.util.List;
import java.util.Optional;
@ApplicationScoped (1)
public class CityConfig {
@Inject
CustomConfiguration configuration; (2)
public String getCity(){
return configuration.city(); (3)
}
public Optional<List<String>> getCities(){
return configuration.cities(); (3)
}
public CustomConfiguration.Other getOther(){
return configuration.other(); (3)
}
}| 1 | @ApplicationScoped sorgt dafür, dass alle Klassen, die diese Klasse per @Inject nutzen, auf dieselbe Instanz zugreifen. |
| 2 | @Inject sorgt dafür, dass eine Instanz von CustomConfiguration zur Verfügung gestellt wird. |
| 3 | Diese GETTER liefern die Konfigurationswerte zurück und sorgen schlussendlich dafür, dass man im Programm Zugriff auf die Konfigurationswerte hat. |
Bevor die Endpoints implementiert werden, wird eine RestConfig-Klasse erstellt, welche die Basis-URL für alle Endpoints des Servers festlegt.
RestConfig
package at.htl.configdemo.control;
import jakarta.ws.rs.ApplicationPath;
import jakarta.ws.rs.core.Application;
@ApplicationPath("api") (1)
public class RestConfig extends Application { (2)
}| 1 | Die @ApplicationPath-Annotation legt die Basis-URL für alle Endpoints fest. In diesem Fall bedeutet es, dass alle Endpoints unter dem Pfad /api erreichbar sind. |
| 2 | Die Klasse RestConfig erweitert Application, was sie zur REST-Konfigurationsklasse macht. Durch die Vererbung von Application kann diese Klasse verwendet werden, um globales Verhalten oder zusätzliche Konfigurationen für Endpoints zu definieren. |
Nun wird die Resource-Klasse implementiert, welche die Konfigurationen als JSON-Objekte per Endpoint zurückgibt.
Resource-Klasse
package at.htl.configdemo.boundary;
import at.htl.configdemo.control.CityConfig;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import java.util.List;
import java.util.Optional;
@Path("config")
@Produces(MediaType.APPLICATION_JSON)
public class CityConfigResource {
@Inject
CityConfig cityConfig; (1)
@GET
@Path("city")
public String getCity(){
return cityConfig.getCity(); (2)
}
@GET
@Path("cities")
public Optional<List<String>> getCities(){
return cityConfig.getCities(); (2)
}
@GET
@Path("other/city")
public String getOtherCity(){
return cityConfig.getOther().city(); (2)
}
@GET
@Path("other/cities")
public Optional<List<String>> getOtherCities(){
return cityConfig.getOther().cities(); (2)
}
}| 1 | @Inject sorgt dafür, dass eine Instanz der CityConfig-Klasse zur Verfügung gestellt wird und somit der Zugriff auf die Konfigurationen ermöglicht wird. |
| 2 | Die einzelnen Endpoints liefern die Konfigurationswerte zurück. |
7. Testen des Projekts
Der Zugriff auf die Konfigurationen und die Endpoints zur Rückgabe der Werte sind implementiert. Um diese zu testen, benötigt man ein requests.http-File.
requests.http
@baseUrl = http://localhost:8080/api/config
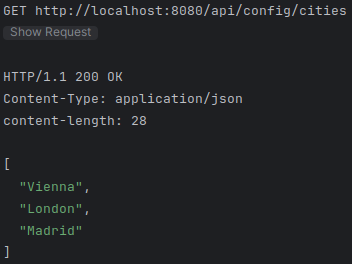
### GET city
GET {{baseUrl}}/city
Accept: application/json
### GET cities
GET {{baseUrl}}/cities
Accept: application/json
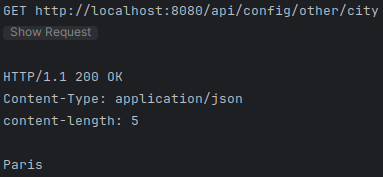
### Get other city
GET {{baseUrl}}/other/city
Accept: application/json
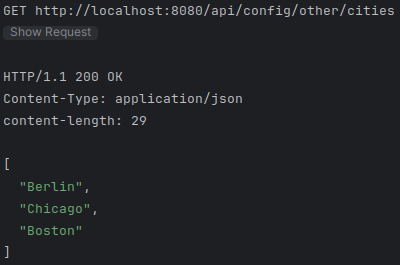
### Get other cities
GET {{baseUrl}}/other/cities
Accept: application/json| Nun muss nur noch der Quarkus-Server gestartet und die Requests im requests.http-File ausgeführt werden. |
./mvnw quarkus:dev clean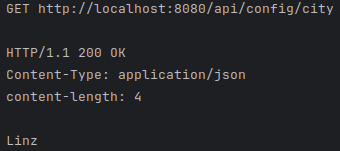
8. Konfigurationen im YAML-Format
| Bei komplexeren bzw. hierarchischen Strukturen empfiehlt es sich, die Konfigurationen im YAML-Format zu definieren. Da dies die Lesbarkeit der Konfigurationen erhöht. |
8.1. application.yaml erstellen
application.properties wird nun von application.yaml abgelöst.
| Die Konfigurationen bzw. die Konfigurationswerte bleiben gleich, nur das Format ändert sich. |
custom:
city: Linz
cities:
- Vienna
- London
- Madrid
other:
city: Paris
cities:
- Berlin
- Chicago
- BostonDamit die Konfigurationen aus dem application.yaml-File gelesen werden können, muss die pom.xml um folgende Dependency erweitert werden:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-config-yaml</artifactId>
</dependency>| Nun sollten beim Testen des Projekts die gleichen Responses wie zuvor zurückgeliefert werden. Siehe hier. |
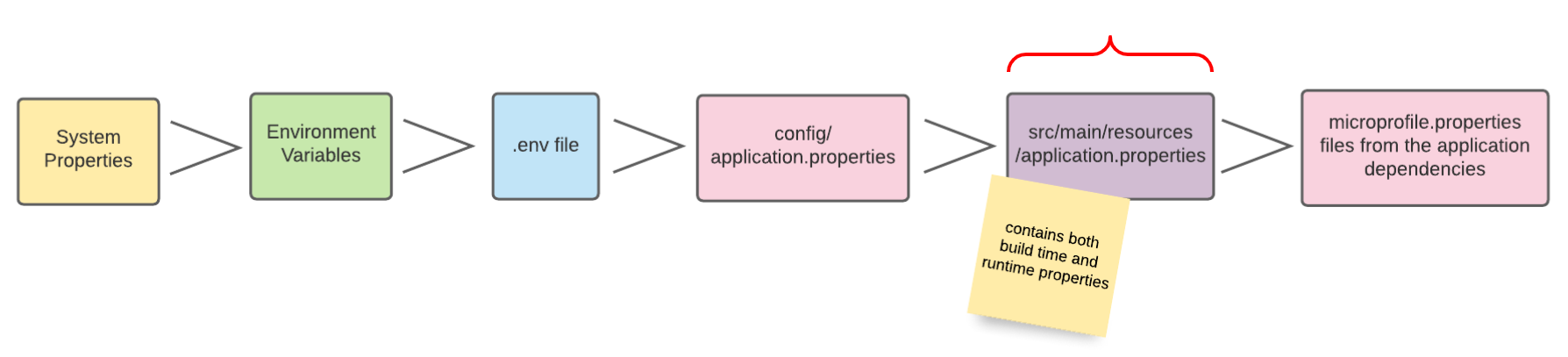
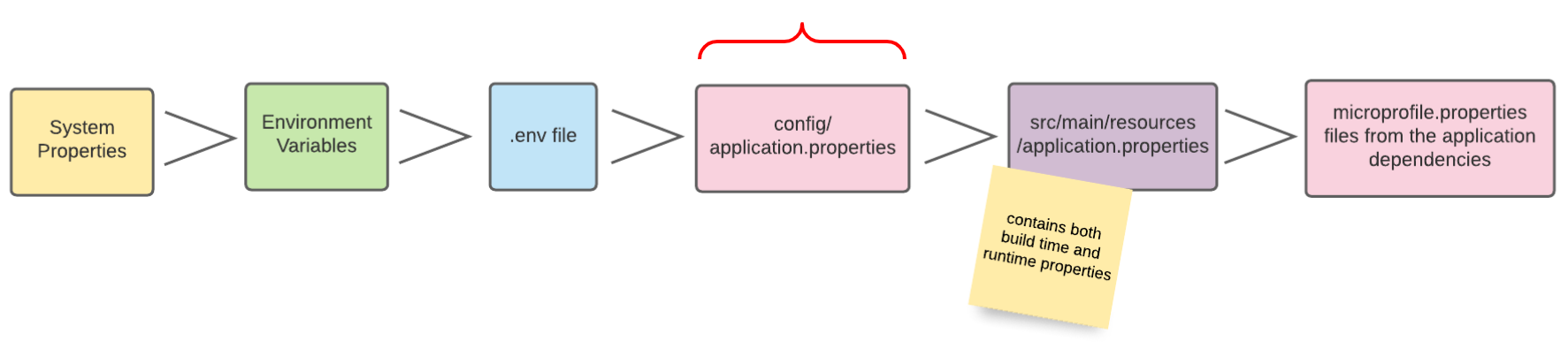
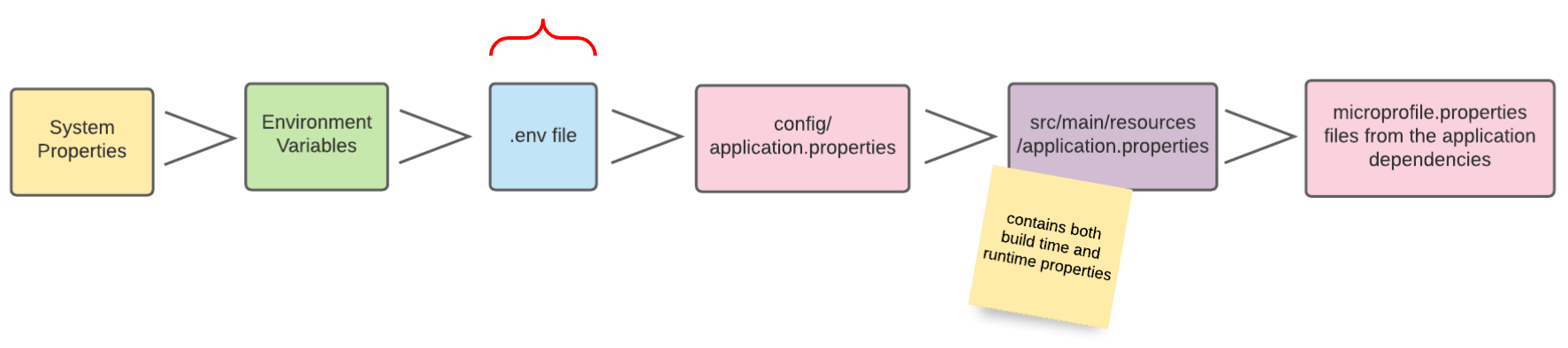
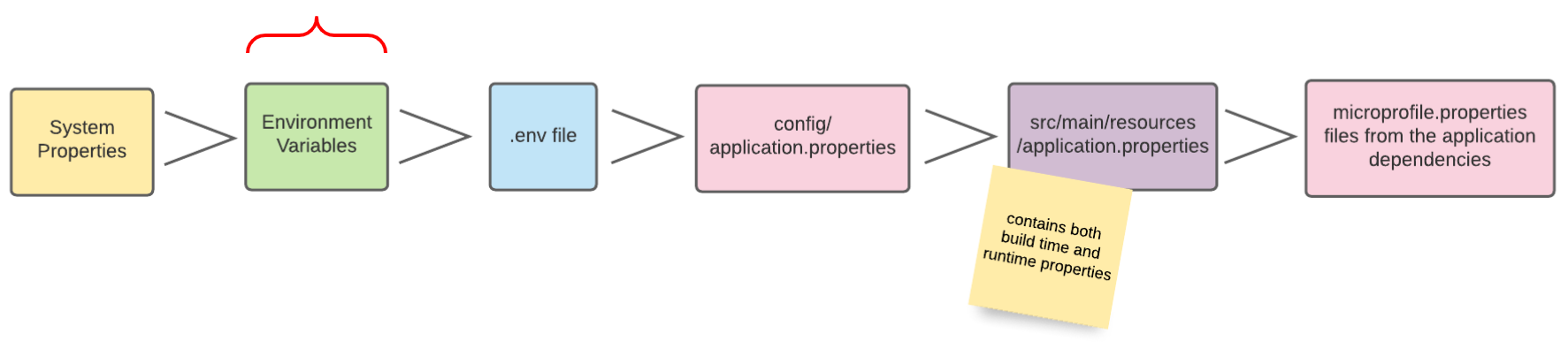
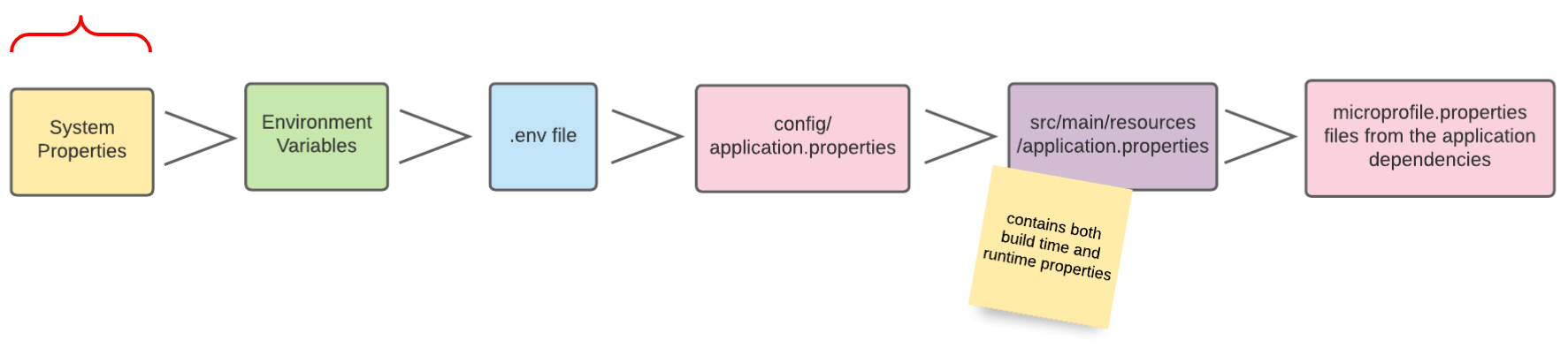
9. Config-Sources
Per Default liest Quarkus Konfigurationseigenschaften aus mehreren Quellen in absteigender Reihenfolge:
-
(400) System Properties
-
(300) Umgebungsvariablen
-
(295) .env-Files
-
(250) application.properties
-
(100) META-INF/microprofile-config.properties
| In diesem Tutorial wird nicht auf die META-INF/microprofile-config.properties eingegangen. Für weitere Informationen bezüglich MicroProfile-Config siehe hier. |
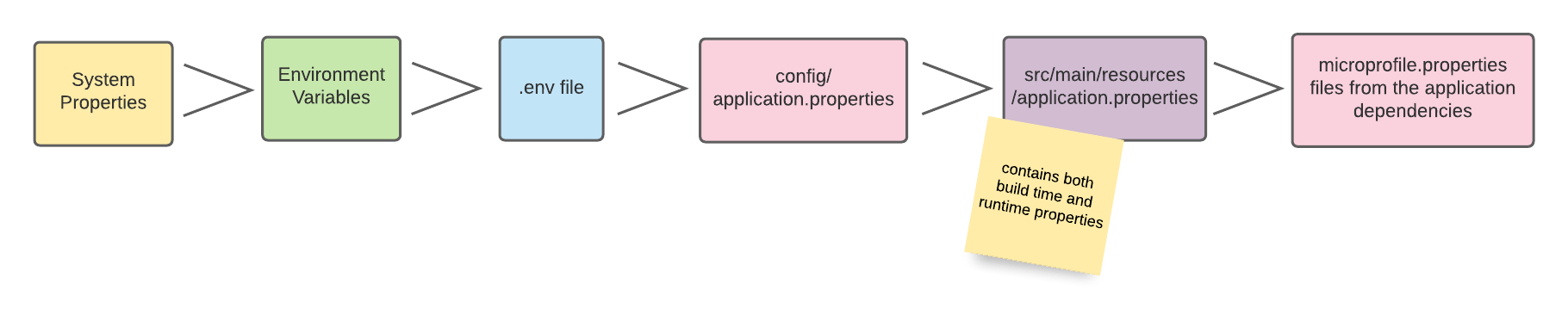
| In der Abbildung sind die verschiedenen Config-Sources dargestellt, aus denen die Konfigurationen gelesen werden können. Je weiter links sich die Config-Source in der Grafik befindet, desto höher ist die Priorität, sprich Konfigurationswerte von weiter links gelegenen Config-Sources überschreiben die Werte von weiter rechts gelegenen Config-Sources. |
Als nächsten Schritt werden die Konfigurationen aus verschiedensten Config-Sources gelesen und im Projekt verwendet. Dies soll als Demonstration der Priorität der einzelnen Config-Sources dienen.
9.1. config/application.properties
9.1.1. Erstellen
Zuerst muss ein Verzeichnis config im Projekt-Root erstellt werden. In dieses Verzeichnis kommt schlussendlich entweder ein application.properties- oder application.yaml-File.
In das application.properties- oder application.yaml-File kommt folgende Konfiguration:
custom.city=Salzburgcustom:
city: Salzburg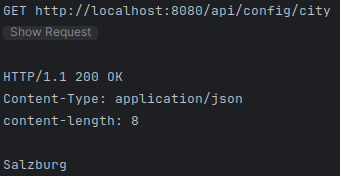
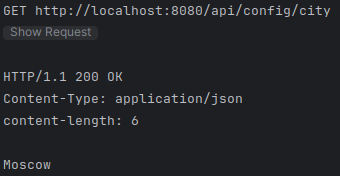
9.2. .env-Files
9.2.1. Erstellen
Das .env-File wird im Projekt-Root erstellt.
In das .env-File kommt folgende Konfiguration:
CUSTOM_CITY=Moscow9.2.2. Testen
Beim Testen des betroffenen Endpoints sollte nun folgende Response zurückgeliefert werden:
Get city
| Das .env-File ist in der Regel bei richtigen Projekten nicht in das Repository zu pushen, da es oft sensible Daten wie Passwörter oder API-Keys enthält. Somit sollte es immer im .gitignore enthalten sein. Wie man das .env-File trotzdem mit weiteren, berechtigten Entwicklern teilen kann, ist hier dokumentiert. |
9.3. Umgebungsvariablen
Umgebungsvariablen können der Anwendung beim Start durch das Schlüsselwort export übergeben werden.
9.3.1. Erstellen
| Hierbei benötigt man ein uber-jar, welches alle Dependencies der Anwendung, den Code der Anwendung und eine ausführbare Main-Klasse (Entry-Point) enthält. Um dieses zu erstellen, muss der folgende Abschnitt Schritt für Schritt durchgegangen werden. |
Zuerst application.properties um folgende Zeile erweitern:
quarkus.package.jar.type=uber-jarOder application.yaml um folgende Zeile erweitern:
quarkus:
package:
jar:
type: uber-jar| Je nachdem, ob mit application.properties oder application.yaml gearbeitet wird, muss die entsprechende Datei erweitert werden. |
./mvnw clean packageNun sollte sich im target-Verzeichnis ein *-runner.jar-File befinden.
Nun kann das jar-File mit folgendem Befehl gestartet und mit einer Umgebungsvariable versehen werden:
export CUSTOM_CITY=Munich ; java -jar target/*-runner.jar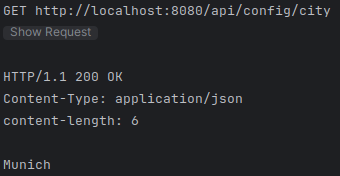
9.4. System Properties
System Properties können der Anwendung beim Start durch das Flag -D übergeben werden.
9.4.1. Erstellen
| Auch bei den System Properties benötigt man ein uber-jar (falls man den Server nicht im Dev-Mode starten möchte), genau wie bei den Umgebungsvariablen. Siehe hier. |
./mvnw quarkus:dev -Dcustom.city=Amsterdamjava -Dcustom.city=Amsterdam -jar target/config-demo-1.0-SNAPSHOT-runner.jar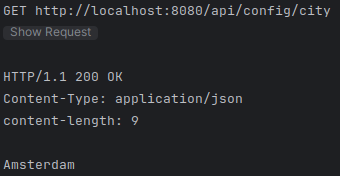
10. Profiles
Profiles ermöglichen es, verschiedene Konfigurationen für verschiedene Umgebungen zu setzen.
10.1. Default Profiles
-
dev
-
Ist im Entwicklungsmodus aktiv (quarkus:dev)
-
-
test
-
Ist beim Ausführen von Tests aktiv
-
-
prod
-
Ist aktiv, wenn man nicht im Dev- oder Test-Modus ist
-
| Außerdem kann man noch Custom Profiles erstellen. Genaueres dazu ist hier zu finden. |
10.2. Wie setzt man Profiles?
10.2.1. *.properties-File
In *.properties-Files werden Profiles wie folgt gesetzt: %{profile-name}.config.name=value
%{profile}.custom.city=Vienna./mvnw quarkus:<profile> clean| Profile ist hierbei der Platzhalter für die jeweilige Umgebung (dev, test, prod, …). |
Je nachdem in welcher Umgebung der Server gestartet wird, wird die entsprechende Konfiguration aus dem *.properties-File verwendet.
10.3. Profile-aware Files
| Um nicht alle Konfigurationen aus verschiedensten Umgebungen in ein *.properties-File zu stopfen, können Konfigurationen für eine bestimmte Umgebung in eine eigene Datei ausgelagert werden (application-{profile}.properties). Für weitere Informationen siehe hier. |
11. Git-Secrets
11.1. Was ist git-secret?
git-secret ist ein Tool, das entwickelt wurde, um sensible Daten wie Passwörter, API-Schlüssel oder Konfigurationsdateien sicher in Git-Repositories zu speichern. Es nutzt GPG-Verschlüsselung (GNU Privacy Guard), um diese Dateien bzw. Daten vor unbefugtem Zugriff zu schützen. Nur autorisierte Benutzer, die über den entsprechenden GPG-Schlüssel verfügen, können die verschlüsselten Inhalte entschlüsseln.
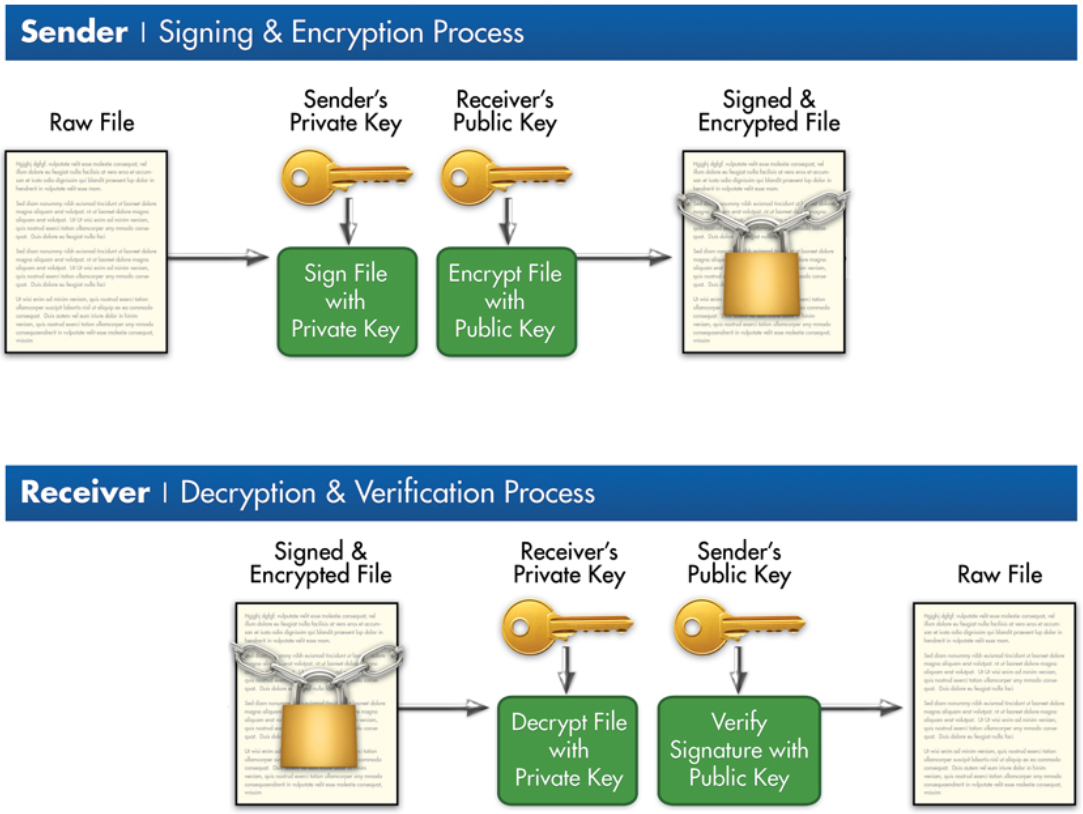
11.2. Welches Problem wird gelöst?
git-secret löst das Problem, dass sensible Daten wie Passwörter, Token oder andere geheime Informationen unbeabsichtigt in Git-Repositories landen können, wo sie für jeden sichtbar sind, der Zugriff auf das Repository hat. Dies ist besonders in öffentlichen Repositories gefährlich.
Durch die Verschlüsselung der sensiblen Dateien stellt git-secret sicher, dass nur autorisierte Personen auf diese Informationen zugreifen können. Es bietet:
-
Sicherheit: Schutz sensibler Daten durch Verschlüsselung.
-
Versionierung: Möglichkeit, Änderungen an sensiblen Daten nachzuverfolgen.
11.3. Wie wendet man git-secret an?
| Das Tutorial muss sich in einem Git-Repository befinden, um git-secret verwenden zu können. |
11.3.1. GPG-Schlüsselpaar erstellen
Zuerst muss ein GPG-Schlüsselpaar (privater und öffentlicher Schlüssel) erstellt werden.
gpg --full-generate-keyAblauf bei der Erstellung eines GPG-Schlüsselpaares
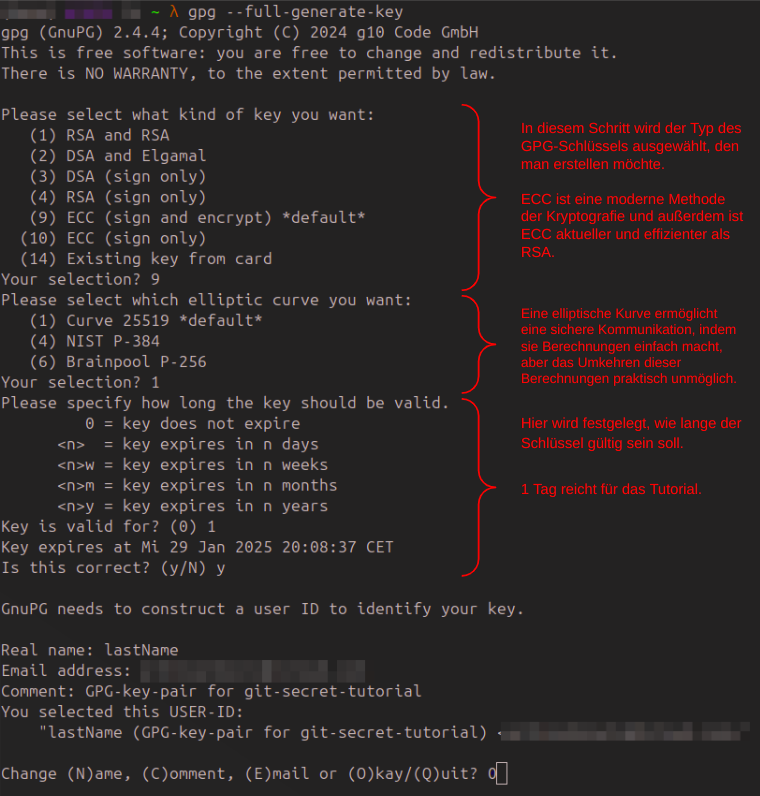
| Die Optionen, welche mit default versehen sind, werden automatisch ausgewählt, wenn man ENTER drückt. |
11.3.2. git-secret initialisieren
Nun wird git-secret im Repository initialisiert. Dadurch wird ein .gitsecret-Verzeichnis erstellt, in dem die GPG-Schlüssel autorisierter Benutzer und andere Metadaten gespeichert werden.
git secret init11.3.3. Benutzer hinzufügen
Nun fügt man sich selbst mit dem GPG-Schlüssel als autorisierten Benutzer hinzu.
git secret tell you@domain.com (1)| 1 | you@domain.com wird mit der eigenen E-Mail-Adresse, die beim Erstellen des GPG-Schlüsselpaars verwendet wurde, ersetzt. |
11.3.4. Datei hinzufügen
Nun wird das .env-File, welches im Tutorial erstellt wurde, hinzugefügt, um es im weiteren Verlauf verschlüsseln zu können.
git secret add config-demo/.env11.3.5. Weitere Benutzer hinzufügen
Um nun anderen Benutzern Zugriff auf die verschlüsselte Datei zu gewähren, müssen folgende Schritte durchgeführt werden:
Zuerst muss der öffentliche GPG-Schlüssel des Benutzers hinzugefügt werden.
gpg --import key.txtSchlussendlich wird noch der Benutzer hinzugefügt.
git secret tell user@domain.com11.3.6. Datei verschlüsseln
Nun wird das .env-File verschlüsselt, sodass nur autorisierte Benutzer darauf zugreifen und die Datei lesen können.
git secret hideNachdem der Befehl ausgeführt wurde, wird das .env-File verschlüsselt und das .env.secret-File erstellt, welches im Repository sichtbar sein darf, da es, dass verschlüsselte .env-File darstellt.
| Dies war nun die Vorgehensweise für das Hinzufügen und Verschlüsseln einer Datei, um diese Datei schlussendlich sicher im Repository zu speichern. |
11.4. Wie entschlüsselt man Dateien mit git-secret?
Nun wird demonstriert wie ein weiterer Benutzer, welcher ebenfalls im gleichen Git-Repository arbeitet, auf die verschlüsselten Dateien zugreifen kann. Sprich es wird dargestellt, wie man von der gegenüberliegenden Seite zum entschlüsselten .env-File kommt.
11.4.1. Datei entschlüsseln
Autorisierte Benutzer können auf die verschlüsselten Dateien zugreifen, indem sie diese mit folgendem Befehl entschlüsseln.
git secret revealNachdem der Befehl ausgeführt wurde, wird das .env.secret-File entschlüsselt und das .env-File kann nun gelesen und bearbeitet werden.
11.5. Erklärung der Befehle
Nun folgt eine detaillierte Erklärung der wichtigsten Befehle in Zusammenhang mit git-secret.
11.5.1. git secret tell
git secret tell fügt den öffentlichen GPG-Schlüssel des angegebenen Benutzers zur Konfiguration von git-secret hinzu. Dadurch wird dieser Benutzer für die Entschlüsselung von verschlüsselten Dateien autorisiert.
Es wird sicherstellt, dass der angegebene Benutzer (mit seinem öffentlichen GPG-Schlüssel) in der Lage ist, die verschlüsselten Dateien zu entschlüsseln, die mit git secret hide verschlüsselt wurden.
Beispiel
Angenommen, ein Benutzer hat einen öffentlichen GPG-Schlüssel mit einer hinterlegten E-Mail: user@example.com. Mit git secret tell user@example.com wird dieser öffentliche Schlüssel in der .gitsecret-Konfigurationsdatei gespeichert.
Wenn dieser Benutzer nun git secret reveal ausführt, wird der private Schlüssel dieses Benutzers benötigt, um die Datei zu entschlüsseln.
11.5.2. git secret hide
Mit git secret hide wird die Datei mit GPG verschlüsselt. Alle öffentlichen GPG-Schlüssel, die in der git secret tell-Konfiguration gespeichert sind, werden verwendet, um die Datei zu verschlüsseln. Dadurch wird die Datei für die entsprechenden Benutzer zugänglich, aber für andere Benutzer bleibt sie verschlüsselt.
Der Inhalt der Datei wird mit dem öffentlichen GPG-Schlüssel der autorisierten Benutzer verschlüsselt. Die verschlüsselte Datei wird dann im Git-Repository gespeichert.
11.5.3. git secret reveal
Bei git secret reveal wird GPG verwendet, um die verschlüsselten Dateien zu entschlüsseln. Um die Datei zu entschlüsseln, benötigt der Benutzer den privaten GPG-Schlüssel, der dem öffentlichen Schlüssel zugeordnet ist, mit dem die Datei verschlüsselt wurde. Das bedeutet, der private Schlüssel des Benutzers, der für die Entschlüsselung durch git secret tell autorisiert wurde, muss auf dem eigenen Rechner vorhanden sein.
12. Docker-Secrets
| Der folgende Abschnitt (Docker-Secrets) ist nicht Teil des Tutorials, sondern dient nur als Zusatzinformation. |
Mit Docker-Secrets kann man sensible Daten wie Passwörter oder API-Schlüssel sicher in Docker verwalten.
Vorteile:
-
Sicherheit (verschlüsselte Speicherung und Übertragung)
-
Zentralisierte Verwaltung
-
Trennung von Code und sensiblen Daten
12.1. Verwaltung von Secrets in Docker
Docker Secrets ermöglichen die Speicherung, Verteilung und Nutzung sensibler Daten in einem Docker-Swarm-Cluster. Die Daten werden verschlüsselt gespeichert und nur an Container weitergegeben, die explizit Zugriff benötigen.
12.1.1. Docker Swarm
| Docker Secrets sind nur im Swarm-Modus verfügbar. |
Docker Swarm ist ein Container-Orchestrierungsdienst von Docker, der es ermöglicht, mehrere Docker-Hosts (Rechner auf denen Docker läuft) zu einem Cluster zusammenzuschließen.
Alternativen wären Kubernetes oder Docker Compose. Der Unterschied zwischen Docker Swarm und Docker Compose ist, dass Docker Compose nur Container auf einem Docker-Host verwalten kann, während Docker Swarm Container von mehreren Hosts zu einem Cluster verbindet und verwaltet.
3 Komponenten des Docker Swarm Clusters:
-
Manager Nodes
-
Verwalten das Cluster und delegieren Aufgaben an Worker Nodes
-
-
Worker Nodes
-
Führen die Container aus
-
-
State Store (vergleichbar mit etcd in Kubernetes)
-
Speichert den Zustand des Clusters
-
Status der Nodes
-
Secrets und Konfigurationen
-
-
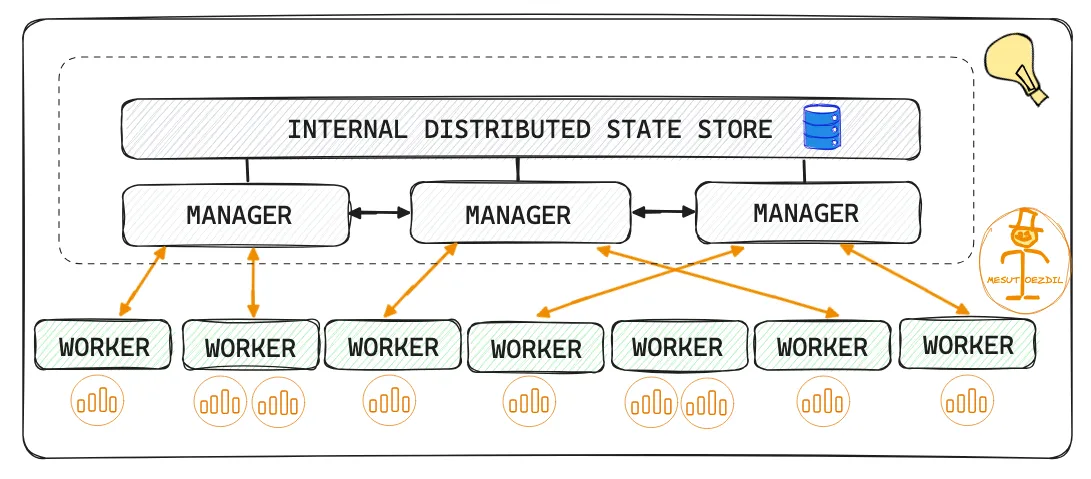
Im Docker Swarm Mode sorgt TLS (Transport Layer Security) für eine sichere Kommunikation zwischen den Manager und Worker-Nodes sowie zwischen den Manager-Nodes untereinander. TLS verschlüsselt die Datenübertragung und stellt sicher, dass die Identität der Knoten überprüft wird, bevor sie miteinander kommunizieren können.
12.2. Docker Secrets erstellen
Zuerst muss ein Swarm-Cluster initialisiert werden, um Docker Secrets zu verwenden.
docker swarm initNun kann ein Docker Secret erstellt werden. Als Beispiel wird ein .env-File als Docker Secret verwendet.
docker secret create my_secret ./.envNun wird ein Docker Service erstellt, der Zugriff zum Docker Secret erhält.
| Docker Services stellen beispielsweise eine Web-App oder einen Datenbank-Server in einem Docker Swarm Cluster dar. Ein Service legt unter anderem fest, wie viele Replicas erstellt werden sollen und welche Secrets verwendet werden. |
docker service create \
--name my_service \
--secret my_secret \
eclipse-temurin:21-jre (1)| 1 | eclipse-temurin:21-jre ist ein Beispiel für ein Docker(-Base)-Image, das als Service erstellt wird. Es kann durch jedes andere Docker-Image ersetzt werden. |
Um den Zugriff auf das Docker Secret zu entfernen, muss der Service aktualisiert werden.
docker service update --secret-rm my_secret my_serviceDas Docker Secret kann mit folgendem Befehl auch gelöscht werden.
docker secret rm my_secret13. Internationalisierung
| Der folgende Abschnitt (Internationalisierung) ist nicht Teil des Tutorials, sondern dient nur als Zusatzinformation. |
i18n steht für "Internationalization" und stellt die Anpassung von Software dar, um sie in verschiedenen Sprachen und Regionen verfügbar zu machen. Das Ziel ist es, nicht nur den Text, sondern auch Datum- und Zahlenformate in mehreren Sprachen bereitzustellen.
Internationalisierung steigert die Benutzerfreundlichkeit für globale Zielgruppen.
| Die folgende Erklärung bezieht sich speziell auf die Internationalisierung in Angular. |
13.1. Übersetzungsdateien
Übersetzungsdateien sind zentrale Bestandteile der Internationalisierung (i18n), die verwendet werden, um Textinhalte einer Anwendung in verschiedene Sprachen zu übersetzen. Sie enthalten Key-Value-Paare, bei denen der Key der Platzhalter für den Text ist und die Value die übersetzte Version des Textes in der jeweiligen Sprache.
Bei Webanwendungen werden Übersetzungsdateien häufig im JSON-Format gespeichert, aber auch andere Dateiformate wie YAML können verwendet werden. Diese Dateien sind typischerweise nach der Sprache strukturiert (z. B. en.json für Englisch, de.json für Deutsch).
{
"welcome": "Willkommen",
"user": "Hallo, {{name}}!", (1)
"header": {
"home": "Startseite",
"about": "Über uns",
"contact": "Kontakt"
}
}| 1 | Platzhalter können in den Übersetzungsdateien verwendet werden, um dynamische Inhalte zu unterstützen. In diesem Fall ersetzt der Platzhalter {{name}} den Benutzernamen. |
{
"welcome": "Welcome",
"user": "Hello, {{name}}!",
"header": {
"home": "Home",
"about": "About Us",
"contact": "Contact"
}
}Die Übersetzungsdateien werden im src/assets/i18n-Verzeichnis gespeichert.
Im angular.json-File muss nun das assets-Directory definiert werden, um auf die Übersetzungsdateien zugreifen zu können.
{
...
"projects": {
"i18n-demo": {
...
"architect": {
"build": {
...
"options": {
...
"assets": [
"src/assets", (1)
{
"glob": "**/*",
"input": "public"
}
],
...
},
...
}
}
}
},
...
}| 1 | In diesem Fall wird definiert, dass der src/assets-Folder beim Bauen des Projekts in das Build-Verzeichnis kopiert wird. |
13.2. Implementierung
13.2.1. Bibliotheken installieren
Zuerst muss die @ngx-translate/core- und die @ngx-translate/http-loader-Bibliothek installiert werden, welche für folgendes benötigt werden:
-
@ngx-translate/core
-
Kernkomponente für die Übersetzungslogik
-
Funktionen:
-
Übersetzung verwalten
-
Sprache wechseln
-
Parameterisierte Übersetzungen
-
-
-
@ngx-translate/http-loader
-
bietet Möglichkeit, Übersetzungsdateien aus einem externen Verzeichnis wie src/assets/i18n/ zu laden
-
Ergänzt die @ngx-translate/core-Bibliothek
-
npm install @ngx-translate/core @ngx-translate/http-loader13.2.2. AppModule konfigurieren
import { NgModule } from '@angular/core';
import { BrowserModule } from '@angular/platform-browser';
import { AppRoutingModule } from './app-routing.module';
import { AppComponent } from './app.component';
import {HttpClient, HttpClientModule} from '@angular/common/http';
import {TranslateHttpLoader} from '@ngx-translate/http-loader';
import {TranslateLoader, TranslateModule} from '@ngx-translate/core';
export function HttpLoaderFactory(http: HttpClient) {
return new TranslateHttpLoader(http); (1)
}
@NgModule({
declarations: [
AppComponent
],
imports: [
BrowserModule,
AppRoutingModule,
HttpClientModule,
TranslateModule.forRoot({ (2)
loader: {
provide: TranslateLoader,
useFactory: HttpLoaderFactory,
deps: [HttpClient]
}
})
],
providers: [HttpClient],
bootstrap: [AppComponent]
})
export class AppModule { }| 1 | Die Factory-Funktion HttpLoaderFactory wird verwendet, um eine Instanz des TranslateHttpLoader zu erstellen, die schlussendlich verwendet wird, um Übersetzungsdateien zu laden. Hierbei ist wichtig, dass sich die Übersetzungsdateien im src/assets/i18n/-Verzeichnis befinden. Ansonsten muss der Pfad in der Factory-Funktion angepasst werden. |
| 2 | Dieser Code konfiguriert das @ngx-translate-Modul, indem ein Loader definiert wird, welcher die Übersetzungsdateien lädt. Der TranslateLoader wird durch die Factory-Funktion HttpLoaderFactory bereitgestellt, die den TranslateHttpLoader verwendet, um die Dateien über HTTP zu laden. Der TranslateHttpLoader verwendet schlussendlich den HttpClient, um die HTTP-Anfragen auszuführen bzw. um die Übersetzungsdateien zu laden. |
13.2.3. Konfigurationswerte in Komponenten verwenden
import { Component } from '@angular/core';
import {TranslateService} from '@ngx-translate/core';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
standalone: false,
styleUrl: './app.component.css'
})
export class AppComponent {
username = 'John Doe';
constructor(private translate: TranslateService) { (1)
translate.setDefaultLang('de');
}
switchLanguage(lang: string) {
this.translate.use(lang); (2)
}
}| 1 | Der Konstruktor injiziert den TranslateService, der verwendet wird, um die Sprache der Anwendung zu ändern und um auf die Werte der Konfigurationen zuzugreifen. Zusätzlich wird die Default-Sprache auf Deutsch gesetzt. |
| 2 | Die Methode switchLanguage wird verwendet, um die Sprache der Anwendung zu ändern. Hierbei wird die use-Methode des TranslateService verwendet, um die Sprache auf die gewünschte Sprache zu setzen. |
<div>
<h1>{{ 'welcome' | translate }}</h1> (1)
<!-- Displaying dynamic user greeting with a placeholder -->
<p>{{ 'user' | translate: { name: username } }}</p> (2)
<div>
<nav>
<ul>
<li><a href="#">{{ 'header.home' | translate }}</a></li>
<li><a href="#">{{ 'header.about' | translate }}</a></li>
<li><a href="#">{{ 'header.contact' | translate }}</a></li>
</ul>
</nav>
</div>
<button (click)="switchLanguage('de')">Deutsch</button>
<button (click)="switchLanguage('en')">English</button>
</div>| 1 | Die translate-Pipe wird verwendet, um die Übersetzungen in der View anzuzeigen. Hierbei wird der Key der Übersetzung als Argument übergeben. |
| 2 | Platzhalter können in den Übersetzungsdateien verwendet werden, um dynamische Inhalte zu unterstützen. In diesem Fall wird der Platzhalter {{name}} durch den Benutzernamen ersetzt. |